Compression
CS240E: Data Structure and Data management (Enriched)
David Duan, 2019 Winter, Prof. Biedl
CompressionCS240E: Data Structure and Data management (Enriched)David Duan, 2019 Winter, Prof. BiedlEncoding BasicsMotivationMeasuring PerformanceFixed-Length Encoding/DecodingVariable-Length Encoding/DecodingPrefix-FreeDecoding of Prefix-Free CodesEncoding From the TrieHuffman EncodingMotivationProcedureAnalysisProof: Huffman returns the "best" trieRuntime AnalysisExercisesRun-Length EncodingStrategyEncodingDecodingAnalysisExercisesLempel-Ziv-WelchStrategyEncodingDecodingAnalysisExercisesSummary Move-To-Front TransformMotivationProceduresAnalysisInput: Long RunsOutput: Uneven DistributionAdaptive DictionaryRuntimeExerciseBurrows-Wheeler TransformMotivationEncodingCyclic ShiftStrategyPseudocodeBzip2PipelineAnalysis
Encoding Basics
Motivation
Problem How to store and transmit data?
- Source Text: The original data, string of characters from the source alphabet .
- Coded Text: The encoded data, string of characters from the coded alphabet .
- Encoding: An algorithm mapping source texts to coded texts.
- Decoding: An algorithm mapping coded texts back to their original source text.
Measuring Performance
The main object for compression is to make small.
We look at the compression ratio .
In this course, we usually let , and we focus on physical, lossless compression algorithm, as they can safely be used for any application.
Fixed-Length Encoding/Decoding
Fixed-length encoding makes the decoding process easy, as we could break into pieces and translate each piece back to the original. However, the compression ratio is not optimal.
Example: Caesar Shift, ASCII
Variable-Length Encoding/Decoding
More frequent characters get shorter codewords.
Example: Morse Code (which can be represented as a trie), UTF-8 encoding (which can handle more than 107000 characters using only 1 to 4 bytes).
Prefix-Free
Note that Morse code is not uniquely decodable; it uses additional pauses to avoid ambiguity.
The prefix property requires that there is no whole code word in the system that is a prefix (initial segment) of any other code word in the system. From now on, we only consider prefix-free codes (codes with the prefix property), which corresponds to a trie with characters of only at the leaves.
The codewords need no end-of-string symbol if the code is prefix-free.
Decoding of Prefix-Free Codes
Any prefix-free code is uniquely decodable.
Runtime: . Note that is incremented in the inner while loop. Intuitively, each character we consumed corresponds to one step traversing the trie.
Encoding From the Trie
We can also encode directly from the trie.
Runtime: .
Huffman Encoding
Youtube resource:
- Concise: https://www.youtube.com/watch?v=dM6us854Jk0
- Detailed: https://www.youtube.com/watch?v=ikswC-irwY8 (Stanford)
Motivation
Consider with prefix-free codes
*0 1* *0 1 0 1L O E S
Then the encoded text will be . Observe the length of the code word is
To minimize , we want to put the infrequent characters "low" in the trie.
Huffman encoding is a greedy algorithm which gives us the "best" trie that minimizes .
Procedure
Strategy
We build a mini-trie using two least-frequent characters and treat this trie as a single character with the sum of two children's frequencies being its frequency. Repeat this process until we have exhausted all used characters.
Note that we need to return both encoded text and trie/dictionary, because otherwise we can't decode the text as the algorithm may return many variations of the trie (not unique).
Pseudocode
Analysis
Huffman Code uses two passes: building frequency array and building min-heap.
Huffman Code is not "optimal" in the sense that it
- ignores the fact that we need to send an additional trie, and
- assume we use character-by-character encoding
A correct statement is, Huffman encoding finds the prefix-free trie that minimizes .
Proof: Huffman returns the "best" trie
We do induction on . We want to show that constructed using Huffman satisfies for any trie that encodes .
Base Case: , call them . Then Huffman returns
xxxxxxxxxx*/ \a a'
which is the best possible trie.
Step: We know has the above mini-trie at the bottom. Consider a differen trie with and be the characters that are at the lowest level; and are somewhere else.
Suppose , if we remove them, then both and give tries for alphabet where . Observe is the Huffman trie for . By IH , we get
Otherwise, switch with in and argue on the resulting tree. Details skipped.
Runtime Analysis
Encoding: .
- Build frequency array takes .
- Build min-heap takes .
- Build decoding trie takes .
- Encoding takes .
Decoding: (see 1.4.2).
Exercises
- Huffman is a [ single / multi ] - chararcter encoding algorithm.
- Huffman uses [ fixed / variable ] - length codeword.
- Huffman requires [ 1 / 2 / 3 ] passes through the text.
- Describe the procedure before constructing the final trie.
- Describe the procedure for constructing the final trie.
- Analyze the runtime for each step of Q4 & Q5 solutions.
- What is the main goal of Huffman encoding?
- Is the trie returned by Huffman unique? Does this have any implication?
- Given the following frequency array, produce a Huffman trie with :
{'A':10, 'E':15, 'I':12, 'S':3, 'T':4, 'P':13, '\n':1}. - What's the ideal scenario to use Huffman encoding?
Solution
- Single: looking at frequency of each individual character.
- Variable: codewords correspond to leaves with different depth in a trie.
- 2 (one for building trie, one for actual encoding).
- Loop through the input text and build an array of frequencies indexed by
- Initialize an empty min-heap ; for each , insert a singleton tree to with frequency representing ; while has more than one tree, pop the two trees with least frequencies, build a new tree using them as children, set the frequency as their sum; when this ends, we are left with a single tree inside that represents the optimized trie.
- Build frequency array takes ; build min-heap takes ; build decoding trie takes ; encoding takes .
- Find the prefix-trie that minimizes .
- No, not unique; because of this, we need to return both the encoded text and the trie from the algorithm.
- Solution not unique; watch first youtube video for one possible solution.
- Huffman is good when the frequencies of characters are unevenly distributed.
Run-Length Encoding
Strategy
Variable-length & multi-character encoding: multiple source-text characters receive one code-word; the source and coded alphabet are both binary ; decoding dictionary is uniquely defined and not explicitly stored.
Elias Gamma Code
We encode with copies of followed by the binary representation of , which always starts with :
| in binary | encoding | ||
|---|---|---|---|
| 1 | 0 | 1 | 1 |
| 2 | 1 | 10 | 010 |
| 3 | 1 | 11 | 011 |
| 4 | 2 | 100 | 00100 |
| 5 | 2 | 101 | 00101 |
| 6 | 2 | 110 | 00110 |
| ... | ... | ... | ... |
Encoding
Example
.
- .
- Block of 's with length : .
- Block of 's with length : .
- Block of 's with length : .
- Block of 's with length : .
- Block of 's with length .
Thus: .
Pseudocode
Decoding
Example
- First bit , so current bit is .
- Followed by , so we know the block has length . We read and get , so we append zeros to .
- Next, , so we know the block has length . We read and get , so we append ones to .
- Next, there is no zero, just a one, so we know the next block is just a single zero; append zero to .
- Next, , so we know the block has length . We read and get , so we append ones to .
As a remark, let denote the number of zeros we encounter during each iteration, note that we always read bits to get the length of current block.
.
Pseudocode
Analysis
This works very well for long runs. For example, if your string is zeros, then you can use zeros to represent the string:
- One leading to denote it is a zero block,
- leading zeros for the run,
- bits to represent the length in binary.
However, RLE works poorly when there are many runs of length or , because the encoded text might be even longer than the original text. To see this, observe you need three bits to represent a block of length two and five bits to represent a block of length four. In fact, up to , you at most do as well as before.
Thus, this is bad for random bitstring, but good for sending pictures with a lot of white with a few block spots.
Exercises
- RLE is a [ single / multi ] - chararcter encoding algorithm.
- RLE uses [ fixed / variable ] - length codeword.
- RLE requires [ 1 / 2 / 3 ] passes through the text.
- Describe Elias Gamma Code (hint: two parts).
- Describe the encoding procedure.
- Describe the decoding procedure.
- During decoding, if we find initial zeros, how many bits do we need to read afterward?
- What's the best case performance for RLE?
- When is RLE good / bad?
- What's the ideal scenario to use RLE?
Solution
- Multi: it works on a block of code.
- Variable: depends on Elias Gamma code.
- One pass only.
- For a block of length , Elias Gamma code is followed by in binary.
- The first bit tells the bit of the first block; concatenate the Elias Gamma code for each block to produce .
- The first bit tells the bit of the first block; if see a block of zeros, read the following bits and denote it as the length of the block.
- bits.
- A block of zeros can be encoded using zeros.
- Good: pictures with a lot of whites and a few black spots; bad: random bit strings. In particular, up to length , you at most do as well as the original text.
- RLE is good when there are long runs.
Lempel-Ziv-Welch
Huffman and RLE mostly take advantage of frequent or repeated single characters, but we can also exploit the fact that certain substrings show up more frequently than others. The LZW algorithm encodes substrings with code numbers; it also finds substrings automatically. This is used in compress command and GIF format.
Strategy
Always encode the longest substring that already has a code word, then assign a new code word to the substring that is 1-bit longer.
Adaptive Encoding
In ASCII, UTF-8, and RLE, the dictionaries are fixed, i.e., each code word represent some fixed pattern (e.g., ). In Huffman, the dictionary is not fixed, but it is static, i.e., the dictionary is the same for the entire encoding/decoding process (we compute the frequency array beforehand).
However, in LZW, the dictionary is adaptive:
- We start with a fixed initial dictionary , usually ASCII.
- For , is used to determine the th output character.
- After writing the th character to output, both encoder and decoder update to .
In short, the dictionary keeps changing after receiving new information. As a result, both encoder and decoder must know how the dictionary changes.
Encoding
Procedure
- We store dictionary as a trie.
- Parse trie to find the longest prefix already in , i.e., can be encoded with one code number.
- All to the dictionary (this prefix would have been useful), where is the character that follows in . This creates one child in trie at the leaf we stopped.
Example
- Convert , add to as (first available code word as ASCII uses to ).
- Convert , add to as .
- Convert , add to as .
- Convert , add to as .
- Convert , add to as .
- Convert , add to as .
- Convert , done.
Final output: str(bin(65)) + str(bin(78)) + ... + str(bin(129)) where + denote string concatenation.
Pseudocode
Decoding
Procedure
We build the dictionary which maps numbers to strings while reading strings. To save space, store string as code of prefix plus one character. If we want to decode something but it is not yet in dictionary, we know the "new character" for this one must be the first character in its parent.
Example
Start with being ASCII. Convert to .
Convert to ; add to with .
Convert to ; add to with .
Convert to space; add to with .
Convert to ; add to with .
Convert to ; add to with .
Convert This code number is not in yet!
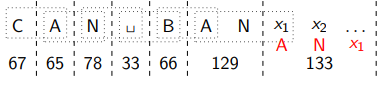
However, we know it would be added to representing where is the unknown next character. After that, we would use as . This tells us ! In general, if code number is not yet in , then it encodes "previous string + first character of previous string".
Pseudocode
Analysis
Encoding: parse each character while going down in trie, so where is the input string.
Decoding: parse each code word while going down in trie, so where is the coded text.
Overall linear time.
Exercises
- LZW is a [ single / multi ] - chararcter encoding algorithm.
- LZW uses [ fixed / variable ] - length codeword.
- LZW requires [ 1 / 2 / 3 ] passes through the text.
- What's the biggest difference between LZW and Huffman/RLE?
- How is the dictionary for LZW different from dictionary for Huffman?
- Describe the procedure for encoding.
- Describe the procedure for decoding.
- What is the special case for decoding?
- Analyze the runtime for LZW.
- What's the ideal scenario to use RLE?
Solution
- Multi: LZW work on repeated substrings.
- Fixed: Each substring is represented by a fixed-length codeword in a dictionary (ASCII).
- One pass: LZW parses and updates the dictionary at the same time.
- LZW takes advantage of repeated substrings whereas Huffman and RLE take advantage of repeated characters.
- Dictionary for Huffman is static, that is, it is fixed once it is built; dictionary for LZW is adaptive, that is, it is frequently updated using the new information given.
- Starting with ASCII (as a trie), parse the trie to find the longest prefix that is already in ; append this to the output and add the prefix with the next character to ; repeat until run out of input.
- Same as encoding, update the dictionary while parsing the text, unless it's the spcial case (see Q8).
- If we want to decode something but it is not yet in dictionary, we know the "new character" for this one must be the first character in its parent. In general, if code number is not yet in , then it encodes "previous string + first character of previous string".
- Both encoding and decoding are basically parsing text while going down in a trie, so linear time.
- LZW works well when there are repeated substrings. It is also very fast.
Summary
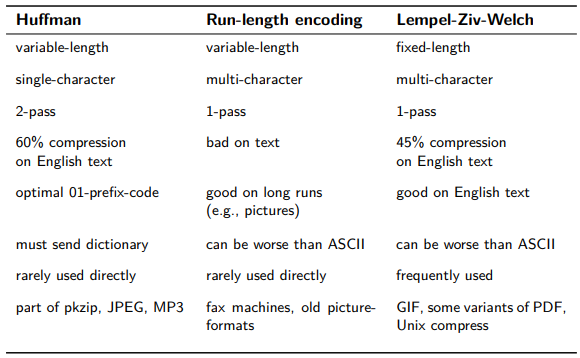
Move-To-Front Transform
Motivation
Recall the MTF-heuristic when storing a dictionary as an unsorted array. The search is potentially slow, but if we have reasons to believe that we frequently search for some items repeatedly, then the MTF-heuristic means a very fast search.
Procedures
Analysis
Input: Long Runs
Suppose the input has long runs of characters. We can view as a sequence of requests for characters in a dictionary that contains ASCII. If we store the dictionary as an unsorted array with the MTF-heuristic, we can transform into a sequence of integers by writing, for each such "request-character" , the index where was found. In genral, if has a character repeating times, then will have a run of zeros. You will see this becomes useful when processing output from Burrows-Wheeler transform.
Output: Uneven Distribution
The output should also have the property that small indices are much more likely than larger indices, presuming we start with ASCII. This holds because the used characters are brought to the front by MTF, so if they are ever used again they should have a much smaller number. Therefore, the distribution of characters in (characters now means number in ) is quite uneven, making it suitable for Huffman encoding.
Adaptive Dictionary
MTF transform also uses adaptive dictionary, since the dictionary changes at every step. However, the change happens in a well-defined manner that only depends on the currently encoded character. Therefore, the encoder can easily emulate this, and no special tricks are needed for decoding.
Runtime
The runtime is propotional to the total time that it takes to find the characters in the dictionary, which is in the worst case, but in practice the performance is much better since frequently used characters should be found quickly.
Exercise
- Explain what MTF-heuristic does.
- When used in BZip2, what assumption do we have for its input? In other words, why do we believe that MTF would have good performance given this input?
- Describe the procedure for encoding and decoding.
- What is the goal for MTF? In other words, what kind of output do we hope to pass on?
Solution.
- Upon searching for an element, move it to the front. Hence the name "MTF".
- After BWT, there will usually be long runs of repeated characters. If we see each of them as one look-up request, searching for the same key repeatedly is very fast in MTF.
- Starting with ASCII, search for each character and append the index where we found it to the output stream until we run out of input characters. Same for decoding, except we are outputting the characters given the index.
- We hope to output numbers with unevenly distributed frequencies because Huffman could take advantage of that. In particular, there will be long runs of zeros if the input has long runs of repeated characters.
Burrows-Wheeler Transform
Motivation
Encoding
Cyclic Shift
Given a string , the th cyclic shift of is the string , i.e., the th suffix of , with the "rest" of appended behind it.
Strategy
Take the cyclic shifts of source text , sort them alphabetically, and then output the last character of the sorted cyclic shifts.
To make BWT encoding more efficient in practice, observe the th character of the th cyclic shift is , so we can read any cyclic shift directly from without doing MSD radix sort.
We said to sort the cyclic shifts, but actually for extracting the encoding, all we need is to describe what the sorting would have been, or put differently, to give the sorting permutation. It turns out that it is better to have the inverse sorting permutation that satisfies the following: if is the sorted order of cyclic shifts, then is the -th cyclic shift, i.e., . In consequence, the th character of the encoding is (or if ).
Pseudocode
TBC
Bzip2
Pipeline
Text : Original Text
- BWT: If has repeated long substrings, then has long runs of characters.
Text
- MTF: If has long runs of characters, then has long runs of zeros.
Text
- RLE: If has long run of zeros, then has unevenly distributed input.
Text
- Huffman: Compresses well since input-chars are unevenly distributed.
Text : Encoded Text
Analysis
Encoding can be slow: BWT bottle-neck (recall if using suffix array via modified MSD radix sorting).
Decoding is fast: Both MTF and BWT can be decoded in without need to anything more complicated than countsort.
Drawback: We need the entire source text at once because BWT needs to sort cyclic shifts. Thus it is not possible to implement bzip2 such that both input and output are streams, i.e., we can't use it for large text that can't fit into memory.