Dictionaries
CS240E: Data Structures and Data Management (Enriched)
David Duan, 2019 Winter
DictionariesCS240E: Data Structures and Data Management (Enriched)David Duan, 2019 WinterMotivationDictionary ADTNaive ImplementationsBinary Search TreesOperationsAnalysisRandom BSTTreapsOperationsAnalysisAVL TreeInsertionProcedurePseudocodeRotation AnalysisRuntimeDrawbacksScapegoat()-TreeWeight -Weight-BalancedChoosing and Working with InsertionProceduresClaimRebuildAnalysisSkip ListsOperationsSearchInsert Complexity AnalysisExpected height of a skip listExpected space of a skip listExpected time for operationsConclusionSplay TreesArray-Based DictionariesFirst CaseSecond CaseSplay Trees: Adaptive BSTOperationsAmortized AnalysisHashingBasicsLoad FactorSeparate ChainingImprovementsProbingLinear ProbingQuadratic ProbingTriangular Number ProbingDouble HashingCuckoo Hashing
Motivation
Dictionary ADT
A dictionary is a collection of key-value-pairs (KVP) with operations
search(k), orfindElement(k)insert(k, v), orinsertItem(k,v)delete(k), orremoveElement(k)
We assume that each key can be stored in space and compared in time and all keys in a dictionary are distinct.
Naive Implementations
- Unsorted list/array: insert, search, delete.
- Sorted list/array: insert, search, delete.
Binary Search Trees
A BST is a binary tree (where each node stores a KVP) that satisfies the BST order property: key(T.left) < key(T) < key(T.right) for all node T.
Operations
Search
- If the node is NIL, return.
- If current node has a key equal to the target key, return current node.
- If current node has a key less than the target key, search the left subtree.
- Otherwise, search the right subtree.
Insert
- If the node is NIL, construct a new node with given KVP.
- If the node's key equals the target key, renew its value.
- If the node's key is less than the target key, insert KVP to the left subtree.
- Otherwise, insert KVP to the right subtree.
Delete
- If the target node is a leaf, remove it.
- If the target node only has one child, promote its child to its position.
- Otherwise, swap the node with its in-order successor (or predecessor), which is the left-most node in its right subtree, then delete the node (which is now a leaf).
Remark
In this course, deletion is not studied. Instead, we use lazy-deletion, replacing the node to be deleted with a "dummy" and keeping the overall structure unchanged. We also keep track the number of dummies, , and rebuild the entire data structure if . Note rebuild can happen only after deletions, which makes the amortized overhead for rebuilding per deletion. Since rebuild with only valid items, this can be done within time. Note that when a node is marked as "dummy", you might still want to preserve its key for comparisons.
Analysis
Let denote the height of a BST. Define and when is a singleton.
- Worst case: .
- Best case: .
- Average case: , see below.
Average Case Analysis
Given , we want to build a BST. Suppose the node inserted first has key .
By BST ordering principle, will in the left subtree and will in the right subtree. Thus, the left subtree has size and the right subtree has size .
Let denote the height of a BST with nodes, . Since is unknown, we take the expected value of the expression above:
- Summation: can range from to .
- : each value of has probability as there are possible values.
- : we want to consider the maximum of two subtrees.
Let for better notation. If lies within and (this has probability), then the size for both subarrays is bounded above by , i.e., in this case:
This is similar to our quick-select proof.
Lower Bound for Search
We can also prove the lower bound for comparison-based search using decision trees.
For a correct comparison-based search, there are possible outputs, which correspond to leaves in our decision tree. We know the minimum height for a binary tree with leaves is , so the lower bound for comparison-based search is .
Random BST
Again, we could use randomization to improve the theoretical performance of BST. A random binary search tree of size is obtained in the following way: take a random permutation of , and add its elements, one by one, into a BST.
A random BST can be constructed in time (by doing insertions); in a random BST, search takes expected time.
Treaps
Treap is a balanced BST, but is not guaranteed to have height as .
The idea is to use randomization and binary heap property to maintain balance with high probability. The expected time complexity for search, insert, and delete is .
Every node of a Treap maintains two values:
- Key which follows standard BST ordering (left smaller and right greater)
- Priority which is a randomly assigned value that follows max-heap ordering property.
In short, a Treap follows both BST ordering property and max-heap ordering property.
Operations
Search(k) - Same as an ordinary BST, with complexity .
Insert(k)
- Randomly pick a priority in for .
- Perform insertion of as an ordinary BST.
- Fix the priority (max-heap order property) with rotations, i.e., locally rearrange the BST while keeping the BST order property.
Rotation
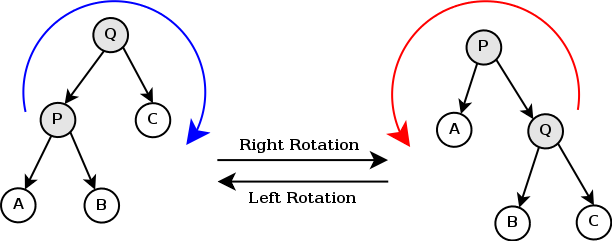
The tree rotation renders the inorder traversal of the tree invariant. For more details, check out rotation section on AVL tree.
Note that, because of rebalancing rotations, Treaps hide insertion orders.
Analysis
Treaps don't guarantee a small height, but if the priorities are chosen uniformly on random, then .
AVL Tree
An AVL Tree is a BST with an additional height-balance property: the heights of the left subtree and the right subtree differ by at most . In other words, we require , where means the tree is left-heavy, means the tree is balanced, and means the tree is right-heavy. An AVL tree on nodes has height and can preform search, insert and delete at in the worst case.
Every node of a Treap maintains two values:
- Key which follows standard BST ordering (left smaller and right greater).
- Height which tracks the height of the current subtree (leaf has height ).
It can be shown that it suffices to store at each node, which may save some space but the code gets more complicated.
AVL-search takes just as ordinary BSTs. We cover AVL-insertion extensively.
Insertion
Procedure
- Insert as for a BST.
- Go back up to the root and update heights and check balances. Recall that if the height difference becomes at node , we call unbalanced.
- If some node is not unbalanced: Let and be the descendent on the insert path, apply the appropriate rotation at to bring the middle value of to the root.
Pseudocode
x1AVL-insert(r, k, v)2r: root of the tree3(k, v): KVP to insert451. z <- BST-insert(r, k, v)62. z.height <- 073. while (z is not the root)84. z <- parent of z95. if (|z.left.height - z.right.height| > 1) then106. let y be the taller child of z (break ties arbitrarily)117. let x be the taller child of y (break ties to prefer left-left or right-right)128. z <- restructure(x) // see rotation139. break1411. setHeightFromSubtrees(z)
xxxxxxxxxx31setHeightFromSubtrees(u)21. if u is not an empty subtree32. u.height <- 1 + max(u.left.height, u.right.height)
Rotation
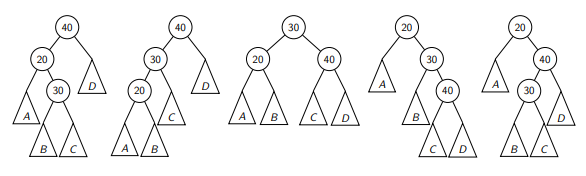
There are many different BSTs with the same keys. Our goal is to change the structure among these three nodes without breaking BST order property, so that the subtree becomes balanced.
xxxxxxxxxx61rotate-right(current)21. newRoot <- current.left32. current.left <- newRoot.right43. newRoot.right <- current54. setHeightFromSubtrees(current), setHeightFromSubtrees(newRoot)65. return newRoot
xxxxxxxxxx61rotate-left(current)21. newRoot <- current.right32. current.right <- newRoot.left43. newRoot.left <- current54. setHeightFromSubtrees(current), setHeightFromSubtrees(newRoot)65. return newRoot
xxxxxxxxxx41rotate-left-right(current)21. current.left <- rotate-left(current.left)32. newRoot <- rotate-right(current)43. return newRoot
xxxxxxxxxx41rotate-right-left(current)21. current.right <- rotate-right(current.right)32. newRoot <- rotate-left(current)43. return newRoot
xxxxxxxxxx211restructure(x)2x: node of a BST that has a grandparent, i.e., the lowest node in (x, y, z) triple.340. let y and z be the parent and grandparent of x51. switch:67z82. y => return rotate-right(z)9x10z123. y => return rotate-left-right(z)13x14z164. y => return rotate-right-left(z)17x18z205. y => return rotate-right(z)21x
As a remark, the middle key of becomes the new root.
Analysis
Runtime
AVL-search takes as usual.
Claim. If an AVL-tree after insertion is unbalanced at , then this rotation makes subtree of balanced and reduces its height.
Thus, AVL-insert takes overall:
- Constant time per rotation.
- At most rotations (one per level).
- In fact, one rotation is all we need (according to the claim).
Drawbacks
- Not space efficient: extra space to cache height.
- Height roughly but we want the tree to be as close to as possible.
- Nearly almost all insertions require a rotation, which add up and take quite some time.
Scapegoat()-Tree
A scapegoat tree is a self-balancing BST that provides amortized insertion, height, and no rotation involved.
Instead of small incremental rebalancing operations used by most balanced tree algorithms, scapegoat trees rarely but expensively choose "scapegoat" and completely rebuild the subtree rooted at the scapegoat into a complete binary tree. Thus, scapegoat trees have worst-case update performance.
Weight
-Weight-Balanced
Recall that a BST is said to be weight-balanced if half of the nodes are on the left of the root and half on the right. An -weight-balanced node is defined as meeting a relaxed weight balance criterion:
A BST that is -weight-balanced must also be -height-balanced, that is,
By contraposition, a tree that is not -height-balanced is not -weight balanced.
Scapegoat trees are not guaranteed to keep -weight-balance at all times, but are always loosely -height-balanced in that
Choosing and Working with
- We choose the constant between and keep it fixed.
- As , .
- To maintain height-balance property during insertion, every node stores , the number of nodes in subtree of .
Insertion
Procedures
- Insert as for a BST.
- On each node along insertion path, update height and deposit a "token". Note that, this token is just analysis purpose and is not needed in practice.
- If height-balance property is violated, i.e., , we completely rebuild some subtree.
Claim
Claim. If the insertion path has height , then there exists some node on that path satisfying .
Proof. We show the contrapositive. Assume for all . Then
Thus, .
Rebuild
Let be the highest node with . Rebuild the tree at . Afterwards, we get for all nodes on path. After a complete rebuild, remove tokens at and all its descendents.
Analysis
We show the amortized time for insertion is using potential function.
Assume constant so big (i.e., largest in all -expressions) that
- Rebuilt takes time
- The height is
- Insert without rebuild takes time .
Let and define . Then
Amortized time of insertion without rebuild:
Amortized time of insertion with rebuild:
It can be shown that the number of token at is at least .
Skip Lists
A skip list allows search complexity as well as insertion complexity within an ordered sequence of elements. Thus it can get the best of array (for searching) while maintaining a linked list-like structure that allows insertion, which is not possible in an array.
Fast search is made possible by maintaining a linked hierarchy of subsequences, with each successive subsequence skipping over fewer elements than the previous one. Searching starts in the sparsest subsequence until two consecutive elements have been found, one smaller and one larger than or equal to the element searched for. Via the linked hierarchy, these two elements link to elements of the next sparsest subsequence, where searching is continued until finally we are searching in the full sequence. The elements that are skipped are usually chosen probabilistically.
Operations
Search
Remark: This is not really a search, but a find-me-the-path-of-the-predecessors.
xxxxxxxxxx101skip-search(L, k)2L: skiplist; k: key to be searched31. p <- topmost left node of L42. P <- stack of nodes, initially containing p53. while below(p) != null do64. p <- below(p)75. while key(after(p)) < k do86. p <- after(p)97. push p onto P108. return P
Keep going right (line ) until the next key on the current level is no smaller than . Go down a level and repeat.
- Not only we return where we stopped, we return the entire search path (the stack ), or the predecessors of at all levels.
- The stack returned does not contain ; to extract (assume it exists in ), we need
after(top(P)).
Insert
Randomly repeatedlly toss a coin until you get tails. Let be the number of times the coin came up heads; this will be the height of the tower of .
Increase height of skip list, if needed, to have levels.
Search for with skip-search(S, k) to get stack . The top items of are the predecessors of where should be in each list .
Insert after in , and after in for .
Complexity Analysis
Expected height of a skip list
Let be a random variable denoting the height of tower of key .
Recall that the height of tower of key equals the , the number of coin tosses resulted in heads before the first tail, thus:
Expected value of :
Expected value of height of the skip list:
The result gets messy. Instead, we'll prove something related to this:
Plug in (the smallest number that makes a point), we see that:
Hence, the height of a skip list is at with high probability. This roughly means that the expected height of the skip list is .
Expected space of a skip list
The space of a skip list is proportional to , size plus all the tower heights.
The expected space of a skip list is proportional to
Expected time for operations
The number of drop-downs .
The number of forward-steps gets messier, so we use a different approach.
Consider the search path and its reverse . We want to find : I stopped here, how long does it take for me to go back to the beginning?
Let be the top layer, which equals to the height of the skip list. Define to be the expected number of steps to get to some node on on layer . (Looking at some node at some height, we want to know what is the length of from this node to the beginning.)
Note that probability is involved to compute . For example, getting to the left XXX takes 1 step but the right one takes 2 steps:
xxxxxxxxxx31XXX2|3XXX -- XXX
Here is the recursive formula:
: the top layer only has two sentinels; we start at the and never get to .
Recursion:
- The probability that tower has height only depends on the probability where a coin toss resulted in tail, which has probability for a fair coin. Similar the other probability is also .
- The at the end represents the operation of dropping down or moving right.
- Key intuition: We can approach a node from the left only if the node doesn't have anything above that node (take a look at your condition for dropping down and moving forward!)
Thus, time for search is .
Conclusion: the expected time for search and insert (and delete) inside skip list is .
Conclusion
Why do we use skip lists?
- Skip lists perform better for range search.
- Although not much space is saved, skip lists are easier to work with.
- Trees need priority to be well randomized but here the only randomness we rely on is coin flip.
Splay Trees
We now present possibly the best implementation for dictionaries. In reality, requests for certain keys are much more frequent, so we want to tailor the dictionaries so that we can complete those requests faster.
Array-Based Dictionaries
We study two scenarios:
- We know access-probabilities of all items (unrealistic, mostly for motivation).
- We don't (more realistic).
First Case
To store items in an array and make accesses efficient, we would want to put the items with high probability of access at the beginning and items with low probability of access at the end. In other words, we "sort" the array with access probability in descending order.
xxxxxxxxxx51item with lowest probability2|3[ array ]4|5item with highest probability
We define the following terms:
Access: just search, not inserting.
Access-probability: number of access to item divided by total number of accesses.
Access-cost: cost to retrieve item during search, which, in a linear search (starting left), equals .
- Thus, the expected access cost of a certain permutation equals the expected value of the random variable representing access cost.
- Our goal is simple: we want the access cost to be at lowest at possible.
Claim For all possible static ordering, the one that sorts items by non-increasing access probability minimizes the expected access cost. (Easy to prove).
Second Case
If we do not know the access probabilities at design time, we need an adaptive data structure, which updates itself upon being used.
MTF Array Upon searching, move the searched item to the front. This has worst case (when we keep searching for the last item).
Transpose Array Instead of moving all the way to the front, we only do one swap. This still has worst case.
Splay Trees: Adaptive BST
MTF does not work well with BSTs, as rotating leaf elements makes the BST to degrade into linked lists. We use more complicated tree rotations that do not unbalance the tree.
A splay tree is a self-optimizing BST, where after each search, the searched item is brought up two levels (using rotations as AVLs).
Operations
Search/Insert: as in BST, then use rotations as in AVLs.
Amortized Analysis
We want to show that a search/insertion has amortized cost .
Define the potential function , where is a node in the tree and is the size of the subtree with root at . Define the "rank" of , , i.e., .
Actual Time (Overall)
The actual time of search/insert (in term of time units) is one plus the number of rotations.
Amortized Time for One Rotation
We show that the amortized time for one rotation is at most (plus 1 for single rotations, which we don't care), where is the node we inserted or searched, and are the rank () of subtree at before and after the rotation.
The actual time for one rotation is easy: two for zig-zig/zig-zag and one for a single rotation.
For potential difference, let be the parent of , be the grandparent of . Then
Only subtrees of the three nodes involved in rotation changed, so
Before rotation, measures the entire (sub)tree, whereas after rotation, measures the same thing. Thus, and cancel each other:
We can also bound from above: before rotation, so
Detour: Recall denotes the size of subtree with root after rotation, so as RHS measures the size of entire (sub)tree. By concavity of logarithm,
Thus,
Back to main:
Recall actual time for a rotation is 2. Hence, the amortized for zig-zig/zig-zag is:
Amortized Time (Overall)
Now, for two consecutive rotations, the end place of the first rotation equals the start place of the second, i.e., , so terms cancel out:
Summary
Splay trees need no extra space beyond BST; insert and search take amortized time; very good (possibly the best) implementation for dictionaries.
Hashing
And finally, we have hashing.
A hash function maps a key to an integer. A uniform hash functions produces each output with equal possibility. The most common one is the modular hash function for some prime . We store a dictionary in a hash table -- an array of size ; an item with key should be stored in .
Since is finite, many keys may get mapped to the same integer: if we insert into the table but is already occupied, then we get a collision. In this section, we explore strategies to resolve collisions.
Basics
Load Factor
We evaluate strategies by the cost of operations, which is done in term of the load factor . We keep small by rehashing when needed:
- Keep track of and throughout operations.
- If gets too large, create new (twice as big) hash-table, new hash functions and re-insert everything into the new table.
- Rehashing costs but happens rarely enough we can ignore this term when amortizing over all operations.
- Note that we should also rehash when gets too small, so that the space is always .
Separate Chaining
The simplest idea is to use an array of linked-lists.
- Search: average (if all linked-lists have roughly the same size), wost case (if the target is in an exceptionally long linked-list).
- Insert (to the front, can be seen as MTF): worst case.
- Space: given .
When , rebuild the entire data structure.
Improvements
Instead of having external data structure to keep multiple items stored at the same location (chaining), we could use open addressing, so that all elements are stored in the hash table itself. There are two main strategies for open addressing:
- Probing A key can have multiple alternative slots.
- Cucko A key can only have one alternative slot.
Probing
Each hash table entry holds one item, but any key may go in multiple locations. A probe sequence is a sequence of possible locations for key . Insert and Search follow this probe sequence until one empty spot is found (for insertion) or the item is found/DNE (for search).
Suppose we have a function which can give us a probe sequence if we feed it Then search and insert operations are intuitive.
Linear Probing
- Probe sequence: for .
- Advantage: no extra space for linked lists.
- Disadvantage: long row of filled slots will result in bad insert and search performance.
Quadratic Probing
- Probing sequence: for .
- It can be shown (using modular arithmetic) that this misses many slots of the hash table. In particular, the probe sequence contains at most many different values from .
Triangular Number Probing
- Probe sequence: for , for .
- It can be shown (using modular arithmetic) that the probe sequence gives distinct values so it must hit an empty slot.
Double Hashing
We use two uncorrelated hash functions that map keys into , so the probe sequence is . Note that should never be , otherwise we are stuck in an infinite loop. Also the output of should not divide or have a common divisor, so we don't miss any hash table entry.
- Advantage: Avoid repeated collisions and effect of clustering.
- Disadvantage: higher hashing cost.
Cuckoo Hashing
We have two hash functions , and two hash tables and . We maintain the invariant key is always at or . Then search and delete are trivial and take time but insert has to pay the price.