External Memory
CS240E: Data Structure and Data management (Enriched)
David Duan, 2019 Winter, Prof. Biedl
External MemoryCS240E: Data Structure and Data management (Enriched)David Duan, 2019 Winter, Prof. BiedlExternal Memory ModelMemory HierarchiesEMMExternal SortingSortingMulti-Way MergeExternal MergesortLower Bound for External SortingExternal DictionariesMulti-Way Search Tree(2,4) TreePropertiesSearchInsert(a,b) TreePropertiesAnalysis(2,4) Tree \iff Red Black TreeB-TreeB+-TreeMotivation: Storage DS vs. Decision DSB+-Tree: The Decision-Variant of a B-TreeLemma on B^+-Tree SizeWhy Do We Do This?Extendible HashingMotivationTries of BlocksOperationsSearch(k)Insert(k)Discussion
External Memory Model
Memory Hierarchies
Recall from CS251, computers have a hierarchy of different kinds of memories, which vary in terms of their size and distance from the CPU. Ordering from the fastest and smallest to the slowest and largest, we have registers, cache, internal memory, and external memory.
In most applications, only two levels really matter -- the one that can hold all the data items in our problem and the level just below that one. Bringing data items in and out of the higher memory that can hold all items will typically be the computational bottleneck in this case.
In this module, we adapt our algorithm to take the memory hierarchy into account, avoiding transfers as much as possible.
EMM
- Suppose internal memory has size and external memory has unlimited size.
- Fast random access between CPU and internal memory.
- Slow access (only in blocks of size ) between internal and external memory.
- We measure the cost of computation by the number of block transfers between internal and external memory.
External Sorting
David: This section is not being tested on the final exam.
Sorting
Given an array of numbers, we want to put them into sorted order. Assume is huge and is stored in blocks in external memory.
Recall in the RAM model, heapsort gives the optimal time () and space () performance. However, accessing a single location in external memory automatically loads a whole block, so accessing at indices that are far apart is very costly, typically one block transfer per array access.
Mergesort, on the other hand, adapts well to an array stored in external memory. It can be made even more effectively using -way merge, i.e., merging sorted runs into one sorted run.
Multi-Way Merge
Remark.
- The standard merge (used in mergesort) uses .
- We could use for internal memory mergesort, but the extra time for means the overall runtime is no better.
External Mergesort
Let be the number of elements in the array stored in external memory, be the size of internal memory, and be the size of block, i.e., how many elements can we transfer from external to internal memory using one block transfer.
Step I. Create sorted runs of length .
- Loading all elements from external to internal memory takes block transfers.
- Notice sorting takes place in internal memory and we don't care about it in EMM.
Step II. Merge the first sorted runs using -way-merge.
- Each of inside internal memory have size because that's how many we could load using one transfer.
- also has size (this explains the ) and we use it as intermediate storage inside internal memory after selecting smallest elements from .
- When is full, we write it back to an array (different one, we don't want to overwrite the original as we are still in progress of sorting) stored in external storage array and clear .
- After the first -way-merge, the first sorted runs (each of size ) will become a sorted run of size stored in an array in external memory.
Step III. Keep merging the next runs to reduce the number of runs by factor of .
- Again, we don't care about the -way merging because it is in internal memory.
- We need block transfers to write everything back to external memory.
- Note that we need rounds of merging to create a sorted array: originally there are sorted runs; each iteration of -way-merge reduces the number of sorted runs by a factor of , hence the result.
Thus, the total number of block transfers is , as we need to perform rounds of -way-merge and each round of merging requires block transfers (both loading and write back).
Lower Bound for External Sorting
Theorem Sorting elements stored in external memory requires
block transfers.
The ratio is the number of external memory blocks that can fit into internal memory. This theorem is saying that the best performance we can achieve for the sorting problem is equivalent to the work of scannign through the input set (which takes transfers) at least a logarithmic number of times, where the base of this logarithm is the number of blocks that can fit into internal memory.
As a remark, -way mergesort with is optimal, because we are sorting as many (smaller) sorted runs as possible.
External Dictionaries
Multi-Way Search Tree
David: 3.1 is merely a motivation for the following data structures.
Let be a node of an ordered tree. We say that is a -node if has children. We define a multi-way search tree to be an ordered tree that has the following properties:
- Each internal node of has at least two children. That is, each internal node is a -node, where .
- Each internal node of stores a collection of itesm of the form , where is a key and is an element.
- Each -node of , with children , stores items , where .
- Define and . For each item stored at a node in the subtree of rooted at , , we have .
If we think of the set of keys stored at as including the speical keys and , then a key stored in the subtree of rooted at a child node must be "in between" two keys stored at . This simple viewpoint gives rise to the rule that a node with children stores regular keys, and it also forms the basis of the algorithm for searching in a multi-way search tree.
Tree
Let denote keys and denote pointers to subtrees.
- KVPs in subtree have keys less than .
- KVPs in subtree have keys greater than but less than .
- KVPs in subtree have keys greater than but less than .
- KVPs in subtree have keys greater than .
Properties
In using a multi-way search tree in practice, we desire that it be balanced, i.e., have logarithmic height. We can maintain balance in a tree by maintaining two simple properties:
Size property: every node has at most four children.
- -node: KVP & subtrees (possibly empty).
- -node: KVP & subtrees (possibly empty).
- -node: KVP & subtrees (possibly empty).
Depth property: all the external nodes have the same depth.
- All empty subtrees are at the same level.
Enforcing the size property for trees keeps the size of the nodes in the multi-way search tree constant, for it allows us to represent the dictionary stored at each internal node using a constant-sized array. The depth property, on the other hand, maintains the balance in a tree, by forcing it to be a bounded depth structure.
Search
Search is very similar to BST:
Insert
As in BST-Insert, we first find where the node should be added. However, the depth property does not allow the tree to grow downward, so we add it to the list of KVPs stored inside the current node (always a leaf) and perform "fix-ups" if necessary.

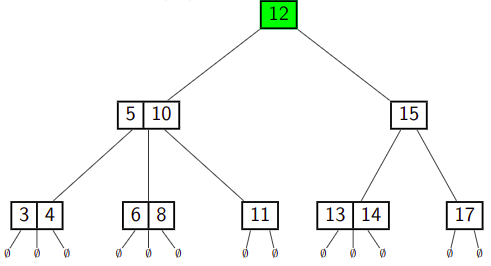
For example, if we insert
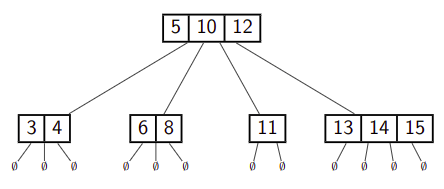 --->
---> 
Tree
Properties
The Tree is a specific type of tree.
An tree satisfies:
- Each node has at least subtrees, unless it is the root, which has at least subtrees.
- Each node has at most subtrees.
- If a node has subtrees, then it stores KVPs.
- Empty subtrees are at the same level.
- The keys in the node are between the keys in the corresponding subtrees.
Additionally, we set the rule that , so operations for trees will work just like for trees, after re-defining underflow/overflow to consider above constraints.
Analysis
We now analyze the runtime for general trees.
Search
- We find the appropriate subtree for recursion in internal memory: . Searching sorted array takes as we know the number of KVPs are bounded above by .
- Since search takes at each level, overall it takes . Since we don't care about what's happening in internal memory, the number of block transfers is .
Insert
- The initial search takes with block transfers.
- The splitting takes worst case (we split at each level).
- Under the key assumption where each node fits into one block, the overall number of block transfers is again .
Height
Suppose we have an tree of height . Note tha we don't count empty subtrees as a level. We want to build an tree with as few nodes as possible but still reach height to form a relationship between , the number of KVPs, and , the height of trees.
At layer 0, we have one node (root) and at least 1 KVPs (recall root is special).
At layer 1, we have at least two nodes (root is special where it can have two subtrees only), each node stores at least KVPs, so overall this layer has KVPs.
At layer 2, we have at least nodes (each node at layer has subtrees at least), each node stores at least KVPs, so overall this layer has KVPs.
At layer 2, we have at least nodes (each node at layer 2 has subtrees at least), each node stores at least KVPs, so overall this layer has KVPs.
Continue this process, at layer , we have at least nodes, each node stores at least KVPs, so overall this layer has KVPs.
Sum up the number of KVPs, we get the number of KVPs given height is at least
Rearranging the equation, the height given of KVPs is at most
Since and the bottom is a constant, we get .
Keep in mind that we have the assumption wehre and , because otherwise the insertion split wouldn't work.
Conclusion
Therefore, runtime for operations is worst case! The number of block transfer is also .
Tree Red Black Tree
David: You are expected to know how the conversion works but not RBT insertion.
Note that we have another data structure with worst-case performance besides AVL tree. We now show (using Red Black Tree) that trees perform better than AVL trees.
A brief introduction on Red Black Tree
Properties:
- Every node is red or black,
- Subtrees of red nodes are empty or have black root,
- Any empty subtree has the same black-depth, i.e., has the same number of black nodes on its path to the root.
To convert a tree to a red-black tree: A -node becomes a black node with red children.
To convert a red-black-tree to tree: the black node and red children become a -node.
In general, red-black-trees provide faster insertion and removal operations than AVL trees as fewer rotations are done due to relatively relaxed balancing.
B-Tree
We have seen the number of block transfers for an tree is . To minimize this, we want to maximize our base . This is the central motivation for -trees: we want to fit as many KVPs as possible into one block: a -tree of order is a --tree, where
B-Trees are basically useless in internal memory (no better than AVL or trees), but are great when used in external memory (e.g., database-related applications), as it minimizes the number of block transfers: recall each operation is done in block transfers, then gives huge saving of block transfers as it minimizes height.
Two Futher Issues
- What if we don't know , the block size? Then we couldn't calculuate explicitly! Solution: we could use Cache Oblivious Trees (not tested).
- What if the values are much bigger than the keys? For example, keys being Facebook ID and values being all the stuff our dearest Mark Zuckerberg has on us? Solution: Take a look at B+ trees.
B+-Tree
Motivation: Storage DS vs. Decision DS
There are two variants of tree-structures:
- Storage-variant (Heap, BST): Every node stores a KVP.
- Decision-variant (Trie, kd-Tree): All KVPs at leaves; internal nodes / edges store only decisions to guide search.
For storage-variant, there usually exists an equivalent decision variant. In internal memory this wastes space (usually twice as many nodes), but we could take advantage of this in external memory.
B+-Tree: The Decision-Variant of a B-Tree
B-tree of order 5:

B+-tree of order 5:

- All KVPs are in the leaves.
- Key at internal nodes holds minimum key from subtree to the right.
- Search/insert need some minor adjustments (no details).
Lemma on B^+-Tree Size
Claim. A B+ tree stores keys, aassuming .
Proof. The bottom layer stores keys; one layer above stores keys; the layer above stores keys... Thus the total number of keys is
Why Do We Do This?
Assume keys are usually fairly small, while values potentially huge. Recall in B-tree, the order is chosen such that a node fits into a block. In a B+-tree, internal nodes can store many more keys than KVPs! Thus the height will be much smaller, so we need fewer block transfer.
Extendible Hashing
Motivation
We store integers in external memory. The regular hashing techniques we had before uses
- expected runtime for insert and search,
- expected number of block transfers.
But! This is amortized! Occationally you need to rehash/rebuild the entire data structure!
Rehashiing takes between and block transfers, which is too slow to our standard.
Tries of Blocks
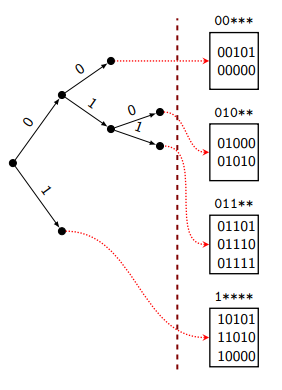
Assume we store integers (hash values) in . Note that we can control the outputs of hash values by choosing appropriate hash function(s).
- We interpret all integers as bitstrings of length .
- Build a trie (directory) of integers in internal memory.
- The trie stops splitting when remaining items fit in one block.
- Each leaf of refers to the block in external memory that stores the items.
Operations
We define
- Global depth: how many steps do I need to walk from the root down to the deepest leaf.
- Local depth (of a block): how many steps do I need to walk from the root down to the given leaf.
In the example above, the global depth is and the top leaf has local depth . The key observation is that the local depth for a block equals the number of mask of that block, i.e., the first few bits of the block that distinguishes itself, or the bits on the search path from root to that block (in the sense of trie search).
Search(k)
- Compute the hash value.
- Convert to a bitstring .
- Trace in trie of blocks to find .
- The leaf you reached contains a reference to the block with in it. Load that block and search for .
Thus, the number of block transfers for search is .
Insert(k)
- Do as above and load the block that should have .
- If the block has space, add to it and return.
- Otherwise, split the block and expand the trie until fits into the block.
Example: Insert(10110):
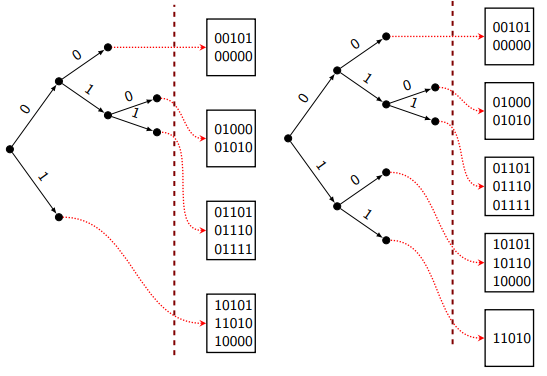
Pseudocode.
[On slides; TBC]
The number of block transfers could be bit but in practice usually 2 to 5:
- Load block once when searching.
- Create two new blocks when splitting.
- Write two new blocks back to external memory.
Discussion
- We usually do block transfer only and we never need a full rehash.
- Note that we assumed the entire trie of directory fits into internal memory.
- We may have empty or underfull blocks, so a bit of space wasted is inevitable.
To further save space, we could expand the trie so that all leaves have the global depth. Note that multiple leaves may point to the same block. Next, we store only the leaves in an array with size where is the global depth of the trie.
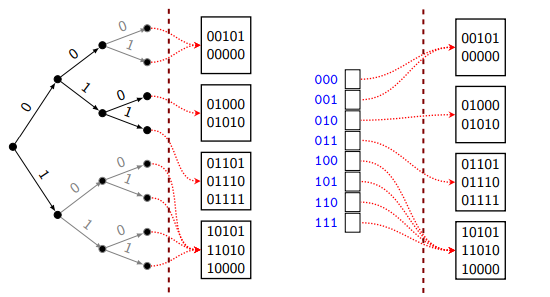
Try to think of doing insertion in a trie (instead of the optimized array thingy) when doing extendible hashing. This is probably easier for your brain.