Pattern Matching
CS240E: Data Structure and Data management (Enriched)
David Duan, 2019 Winter, Prof. Biedl
Pattern MatchingCS240E: Data Structure and Data management (Enriched)David Duan, 2019 Winter, Prof. BiedlMotivationPattern MatchingDefinitionsBrute-Force AlgorithmImprovementKarp-Rabin AlgorithmKarp-Rabin Fingerprint Algorithm (Naive)Karp-Rabin Fingerprint Algorithm (Rolling Hash)Boyer-Moore AlgorithmBad Character HeuristicGood Suffix HeuristicConclusionKnuth-Morris-Pratt AlgorithmMotivationHow the Automaton WorksFailure Array KMP AlgorithmSuffix TreesMotivationSuffix TreePattern MatchingAnalysisSuffix ArrayMotivationPattern Matching in Suffix ArraysBuild Suffix ArrayAnalysis
Motivation
Pattern Matching
Given a text of length and a pattern of length , we return the first such that for , which is the index of the first occurrence of in , or FAIL, if does not occur in .
Definitions
- A substring , , is a string of length which consists of characters in order.
- A prefix of is a substring of for some .
- A suffix of is a substring of for some .
- A border of is a substring with where . In other words, a border of is a substring that is both proper prefix and proper suffix of . We call its length the width of the border.
- A guess or shift is a position such that might start at . Note that the valid guesses initially are .
- A check of a guess is a single position with where we compare to. Note that we must preform checks of a single correct guess, but may make fewer checks of an incorrect guess.
Brute-Force Algorithm
We check every possible guess.
The worst case performance is , as there are valid guesses and checking for each guess (string comparison) takes time.
The runtime for brute-force algorithm is , which is quadratic if is large!
Improvement
To improve the performance, we can break the problem into two parts:
- Preprocessing: we build data structures or extract information that makes query easier, which may take a long time,
- Query: we carry out the original task, which should be very fast as we have already paid the price during the first stage.
The Range Query problem in our previous module can be seen an example of prepocessing.
For Pattern Matching, we can either do preprocessing on the pattern , where we eliminate guesses based on completed matches and mistakes, or on text , where we create a data structure to make finding matches faster.
Karp-Rabin Algorithm
Key Idea We use hashing to eliminate guesses.
- , i.e., there is no need for if hash values differ.
- where is a prime.
Karp-Rabin Fingerprint Algorithm (Naive)
Strategy
The initial hashes are called fingerprints. We compute the fingerprint/hash value (using the ordinary flatten-then-modular approach) for each substring of length in . If this fingerprint equals the fingerprint for the pattern, we them to check if it really is a match; otherwise, we discard the current guess.
Pseudocode
Correctness
We will never miss a match, as .
Complexity
The overall runtime is still worst case as computation (line ) depends on characters.
We didn't really improve anything!
Karp-Rabin Fingerprint Algorithm (Rolling Hash)
Strategy
Suppose in a previous iteration, we have computed , and now we want . Observe . Thus:
Given the hash value of the previous guess, we can compute the hash value of the next guess in constant time!
Pseudocode
Correctness
Correctness for rolling hash comes from modular arithmetic. The rest are identical to before.
Complexity
Worst case is still but this is very unlikely. The expected time is , where we spend doing the initial computations and and during each guess (roughly of them) we perform constant operations.
This is easy and already faster than brute-force, but we can do even better!
Boyer-Moore Algorithm
Key Idea We compare the characters of the pattern and the substring from text from right to left, skipping the unnecessary comparisons by using the good-suffix and bad-character heuristics.
We compare the end characters of the pattern with the text. If they do not match, then the pattern can be moved on further. If the characters do not match in the end, there is no need to do further comparisons. In addition, we can also see what portion of the pattern has matched (matched suffix), so we could utilize this information and align the text and pattern by skipping any unnecessary comparisons. At the time of a mismatch, each heuristic suggests possible shifts, and the BM algorithm shifts the pattern by considering the maximum shift possible due to two heuristics.
Notation In the following examples, let ! denote the mismatched character and # denote the starting position of after our shift .
Bad Character Heuristic
This heuristic is based on the mismatched character.
If there is a mismatch between the character of the pattern and the text, then we check if the mismatched character of the text occurs in the pattern or not. If this mismatched character does not appear in the pattern, then the pattern will be shifted next to this character; if the character appears somewhere in the pattern, we shift the pattern to align with the occurrence of that character with the bad character of the text string.
Example I
The mismatched character is at , where we see . Since , we can shift to , i.e., our next guess is , since substrings all contain but does not. This saves us many unnecessary comparisons.
#i 0 1 2 3 4 5 6 7 8 9 0 1=====================================================T | a | c | a | c | a | b | a | c | a | b | a | b | a |=====================================================P | a | c | a | c | a | c |=====================================================| a | c | a | c | a | c |=====================================================✗
Example II
We have a matched suffix and mismatched character at . Since , we shift to .
xxxxxxxxxx#i 0 1 2 3 4 5 6 7 8 9 0 1=====================================================T | a | c | a | d | a | c | a | c | a | b | a | b | a |=====================================================P | a | c | a | c | a | c |=====================================================| a | c | a | c | a | c |=====================================================✗ ✓ ✓
Example III
We have a matched suffix and mismatched character at . This time and the only occurrence of is at . Thus, we shift to to align and .
xxxxxxxxxx# !i 0 1 2 3 4 5 6 7 8 9 0 1=====================================================T | a | c | a | d | a | c | a | c | a | b | a | b | a |=====================================================P | a | d | a | c | a | c |=====================================================| a | d | a | c | a | c |=====================================================✗ ✓ ✓
Example IV
We have a matched suffix and a mismatched character at . This time however, there are two occurrences of in , each at and . We always shift the minimal amount to avoid missing any possible match. In this case, we prefer , because we only shift character, where shifts (and missed the matched string at ! I came up with this example to show the importance of align the bad character to its last occurrence in the pattern).
xxxxxxxxxx# !i 0 1 2 3 4 5 6 7 8 9 0 1=====================================================T | a | a | c | a | c | c | c | c | a | b | a | b | a |=====================================================P | a | c | a | c | c | c |=====================================================P1 | a | c | a | c | c | c |=====================================================P2 | a | c | a | c | c | c |=====================================================✗ ✓ ✓
Last Occurrence Function
In Example IV, we saw the importance of aligning the bad character to its last occurrence in the pattern. Therefore, we need a last-occurrence function , where
For Example IV, , , and for all . When we see the mismatched at , check and shift character.
Boyer-Moore Pseudocode (Bad Character Heuristic)
Remark. Sometimes produces a negative value:
xxxxxxxxxxi 0 1 2 3 4 5 6 7 8 9 0 1=====================================================T | a | b | a | a | b | a | c | c | a | b | a | b | a |=====================================================P | c | a | b | a | b=====================================================✗ ✓ ✓
If we were to align with the last occurrence of in , we would need to shift . To avoid negative shifting, we take , which guarantees that is incremented by at least . This also motivates the Good Suffix heuristic as we could do better than only shifting in the worst case.
Good Suffix Heuristic
This heuristic is based on the matched suffix.
We shift the pattern to the right in such a way that the matched suffix subpattern is aligned with another occurrence of the same suffix in the pattern.
For this heuristic, an array is used. Each entry contains the shift distance of the pattern if a mismatched at position occurs, i.e., if the suffix of the pattern starting at position has matched. In order to determine the shift distance, two cases have to be considered.
- The matching suffix occurs somewhere else in the pattern.
- The suffix of the matching suffix occurs as a prefix of the pattern.
Example I: Align Suffix
xxxxxxxxxx!,#i 0 1 2 3 4 5 6 7 8 9 0 1=====================================================T | l | m | n | n | p | a | ...=====================================================P | s | p | a | a | p | a |=====================================================| s | p | a | a | p | a |=====================================================✗ ✓ ✓
We matched suffix and found a mismatch at , where but . Therefore, we want to shift forward. The intuition is that, after shifting, two characters aligned with and must be , otherwise it is guaranteed to fail. Since occurs in at (recall this is the index where the substring starts), we align with for our next guess.
Example II: Minimal Shifting
xxxxxxxxxx# !i 0 1 2 3 4 5 6 7 8 9 0 1=====================================================T | n | p | a | l | m | n | n | p | a | a | p | a |=====================================================P | n | p | a | n | p | a | a | p | a |=====================================================| n | p | a | n | p | a | a | p | a |=====================================================✗ ✓ ✓
In this example, there are two occurrences of in . We always prefer the minimal amount of shifting to avoid missing possible matches.
Example III: Character Before Suffix
xxxxxxxxxx#,!i 0 1 2 3 4 5 6 7 8 9 0 1=====================================================T | a | b | c | d | e | f | a | a | a |=====================================================P | n | a | a | p | a | a | p | a | a |=====================================================P1 | n | a | a | p | a | a | ...=====================================================P2 | n | a | a | p | a | a | p | a | a |=====================================================✗ ✓ ✓
In this example, we matched suffix and the mismatch occurs at , which tells us that in front of the matched suffix doesn't work. Therefore, shifting to make align with will make us compare with , which we already know from the first iteration that is bad. Thus, we shift to make align with to avoid unnecessary comparisons.
Example IV: Bad Character & Good Suffix
xxxxxxxxxx#,!i 0 1 2 3 4 5 6 7 8 9 0 1=====================================================T | a | b | c | d | e | f | x | a | a |=====================================================P | n | a | a | p | a | a | p | a | a |=====================================================| n | a | a | p | a | a | ...=====================================================✗ ✓ ✓
If we were only to use good-suffix heuristic, we would shift the same way as in Example III. However, the bad-character heuristic tells us does not occur in at all, so we shift to one character after . The previous three examples are designed in the way that we can ignore the bad-character heuristic.
Example V: Suffix of Suffix Matches Prefix of Pattern
xxxxxxxxxx! #i 0 1 2 3 4 5 6 7 8 9 0 1=====================================================T | a | b | c | a | a | b | b | a | b | b | a |=====================================================P | a | c | b | b | a | b | b | a |=====================================================P1 | a | c | b | b | a | b | b | a |=====================================================P2 | a | c | b | b | ...=====================================================✗
The matched suffix is , but is not occurred elsewhere in our pattern . We then search for partial suffix, or suffix of this suffix (which is still a suffix of ), see if any part of it is a prefix for . Note that we only accept when a partial suffix is a prefix of ; anywhere else the partial suffix occurs in are not accepted. Consider the above example. We know is not occurred elsewhere in , so we start searching if a partial suffix is a prefix of . Although does occur, we know the character preceding is a mismatch (otherwise, would occur), so we don't accept this occurrence of in the middle of . Thus, is wrong. The correct shift is , where we see is both a suffix and a prefix of .
Example VI: Together
xxxxxxxxxx! #i 0 1 2 3 4 5 6 7 8 9 0 1=====================================================T | c | h | u | a | c | h | u | p | i | k | a | p | ...=====================================================P | p | i | k | a | c | h | u |=====================================================P1 | p | i | k | a | c | ...=====================================================✗
By bad-character, we would shift forward (recall the argument "" to the function in the previous algorithm). By good-suffix, since there is no suffix of that is also a prefix of , we shift the entire thing past the current location, because we know non-of the substrings would work.
Suffix Skip Array
We can precompute the suffix skip array of amount to shift, where

Then, we can update guess by . This is computable in time (similar to KMP failure function, see below).
Conclusion
- BM works well in practice, even bad-character heuristic alone is often good enough.
- Preprocessing takes : for last-occurrences and for suffix-skip.
- Search takes time (often better in practice).
- Auxiliary space : for last-occurrences and for suffix-skip.
Knuth-Morris-Pratt Algorithm
Motivation
Recall from CS241 (yikes), we could match strings using DFAs. We could embrace the idea of using states to represent our matching progres. In addition, we have a new type of transition (failure):
- Use this transition only if no other fits.
- Does NOT consume a character (like an -transition).
With these rules, computations of the automaton are deterministic (but not formally a valid DFA).
How the Automaton Works
Recall if we are at state , then we have the first characters matched at this moment.
The following automaton helps us match the pattern :
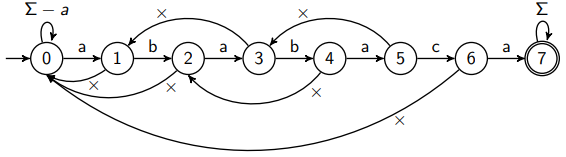
The normal transitions and states are intuitive (same as in CS241). To understand the failure transitions, consider what happens when we feed it the following inputs:
- : Trivial; we get to the accepted state 7.
- : matched so we get to state 2. However, the next character is a mismatch (we see this by comparing the next character in the input string, i.e., , with the character for the valid transition at the current state, i.e., ), so we follow the failure arc from state 2, which sends us back to state 0. We then compare the next character with the character for a valid transition character , which is a mismatch. Thus, we follow the loop and stay in state 0. Intuitively, this means that we need to start from the beginning when we match .
- : matched so we get to state 1. However, the next one is a mismatch, so we don't consume anything and follow the failure arc back to 0. Since next character is and the character for valid transition is also , we can go to state 1. Intuitively, this means that when we start matching , we have already matched an .
- : The first four letters matched, so we are at state 4. Next character is a mismatch, so we follow the failure arc of state 4 to go back to state 2. The transition fails at state 2 again, so we follow the failure arc back to 0. Since , we follow the loop and stay at state 0. This means the same as .
Following the failure arc is equivalent to shifting our pattern forward.
Failure Array
We can compute and store these failure arcs using an array , where the failure arc from state leads to . The indices differ by because we don't need to store the failure arc for state , as it has a loop if the character for valid transition doesn't match. Thus, stores the destination of failure arc originated from state 1 (which is always 0) and stores the destination of failure arc orginated from state .
Brute Force
Since we are basically trying to find the longest proper prefix of that is also a proper suffix of , we could do the following in time (suppose ):

We consider because we want proper suffixes of . is the length of the longest prefix of that is a suffix of .
Example: An Intuitive Way to Compute Failure Array
| New Character | ||||||
| Longest Valid Proper Prefix & Suffix of | ||||||
| Current State and Valid Character Transition |
Let our starting state be and process the first character . There is no valid proper prefix of that is also a proper suffix, so the substring is . Intuitively, if we fail transition for next character, we would go back to state .
| New Character | ||||||
| Longest Valid Proper Prefix & Suffix of | ||||||
| Current State and Valid Character Transition |
We are at state and the new character is . The valid transition character from current state (we look at the previous column!) does not match our new character, so we can't extend the substring. Thus, we stay at with the substring being .
| New Character | ||||||
| Longest Valid Proper Prefix & Suffix of | ||||||
| Current State and Valid Character Transition |
We are still at state and the new character is . This time, the valid transition character (again, last column) matches our new character so we know we can extend our substring. In other words, previous substring plus new character, i.e., is our current longest valid proper prefix and suffix after seeing . We increment our state, so that the destination of the failure arc from state is state .
| New Character | ||||||
| Longest Valid Proper Prefix & Suffix of | ||||||
| Current State and Valid Character Transition |
We are at state and the new character is , which matches the valid transistion character at current state. We add to current substring and increment our state. Note that at any time, the second row could serve as a sanity check to see if your algorithm is wrong.
| New Character | ||||||
| Longest Valid Proper Prefix & Suffix of | ||||||
| Current State and Valid Character Transition |
Following the same logic, characters match so we extend the substring and increment state.
| New Character | ||||||
| Longest Valid Proper Prefix & Suffix of | ||||||
| Current State and Valid Character Transition |
This time, , so we follow the failure arc at state to go back to ; (comparison at state ) so we follow the failure arc at state to go back to . At this point, the substring is empty and our stay at . Note that we don't need to compute for the last state, because if we got there then our text is accepted; we can happily write and move on.
Pseudocode
The loop invariant is that, is the longest valid prefix and valid suffix of pattern after we have seen .
Claim Failure array takes to compute.
Proof. Consider how changes in each iteration of the while loop:
- and both increase by increases.
- decreases as increases.
- increases increases.
Initially and at the end . Thus, the while loop runs less than iterations runtime.
KMP Algorithm
Claim The runtime overall is .
Proof. Failure array can be computed in time. The same analysis shows that the while loop in the main function runs less than iterations as . Thus, the overall runtime is .
Suffix Trees
Motivation
KR, BM, and KMP all try to speed up pattern matching by preprocessing . We can also preprocess the text , especially when we want to search for many patterns within the same fixed text .
Observe that is a substring of iff is a prefix of some suffix of . Thus, we could store all suffixes of in a trie and do a trie-search for pattern matching.
Suffix Tree
- To save space, we use a compressed trie and store suffixes implicitly via indices into .
- Each internal node stores a reference to a leaf.
- We could build a suffix tree in time, but this is too complicated and we are not studying it in this course.
- Note that, if has characters, it will have suffixes (the additional one being ). Thus, the suffix tree has size .
Pattern Matching
Recall in an uncompressed trie of suffixes, we parse until "no such child" or "found as perfix". Similarly in a suffix tree, we parse until
- No such child, return .
- Reached a leaf, check existence,
- Run out of characters, check existence.
Example
Consider the following suffix tree for :
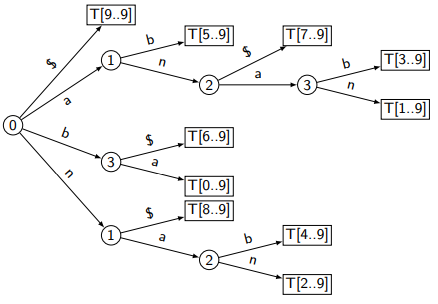
: At node , we see there is no edge/transition for , so "no such child" and return .
: We ran out of characters in and stop at state . Since the node stores a reference to the leaf which stores the longest suffix, i.e., , we check if is in . Note that the lower bound tells us that, if exists, it must start at . We see , thus we found a match.
: We parse and follow the path , then parse to follow that path . We are at a leaf. We know and , but we don't know about , or the rest of , since the "compression" skipped the comparisons for those characters. We do and found they are different. Hence no match.
Check Existence
From the above example, we see that even if we have exhausted characters in or reached a leaf in , we still can't guarantee that exists in without further .
Recall we store suffixes implicitly via indices into . To check if is in , we do , where tells us "if exists, it starts at ". As a side note, we want to make sure , i.e., no overflow (for example, we could do early stop when overflow is detected).
Pseudocode
- indicates which character in are we concerning. In the example above, suppose . In the beginning, tells us we need to follow the transitions from root based on . Thus, we follow branch labeled and arrive at the node labeled (our ). However, , telling us we have exhausted . We then do
strcmpto check the existence of in , which is the longest leaf pointed to by .
Analysis
- Preprocessing takes (blackbox algorithm).
- Search time takes as we are walking down the trie and consume one character from each time; the loop stops after at most iterations.
- We need extra space as the suffix tree has size .
Suffix Array
Motivation
We want a pattern matching algorithm that is almost as fast as suffix trees but requires much less space and is easier to work with.
We sort all suffixes of text and store the sorted indices in an array , i.e., iff suffix is the -th smallest suffix. For pattern matching, we need to find among suffixes that are in sorted order. With binary search, we could achieve this in comparison. However, notice each comparison is a strcmp of and , which takes time. Thus, runtime is (compared to for suffix trees). This is the price we pay for space efficiency.
Pattern Matching in Suffix Arrays
Consider the following example. Given , we sort all its suffixes:
The suffix array here is . If we are given this, we could do a simple binary search to determine if exists in .
For example, if we were to search if exists in , the above algorithm runs as follows:
- , . (.)
- First iteration: , . returns as . .
- Second iteration: , . returns . Success.
Build Suffix Array
How do we efficiently build the suffix array? Suppose we have .
Given the unsorted suffix array (left), we countSort by first letter. Recall it is stable:
Next, we partition the (partially) sorted array into groups: (starting with ), (starting with ), (start with ), and (starting with ).
For each group, we determine the partners (the unsorted portion) and their indices. For example, the partners of the first group are: (red denotes the sorted portion and green denotes partners)
The key observation is that each partner is also a suffix of ! Our previous countSort has already sorted these partners as well! We put sorted indices into another array. For example, the suffix is now at the -th place in the suffix array after sorting the first character, so it has value in the following table. Alternatively, we are recording where each got moved to after sorting:
Then, we can sort by indices of partners. For example, for group 1, has index , has index , has index , and has index . Thus, we reorder the first four entries of the suffix array to
We do the same for the rest of the suffixes. An interesting observation is that since the full string is located at after sorting, no partner would have as their index, i.e., is disappeared from column . Also, has no partner, so we give its partner to make sure it has the smallest partner index.
Note that we need to update the auxiliary array after every countSort:
We repeat this process until all suffixes are sorted:
Observe the first countSort sorts all first digits and the second countSorts sorts one more digit in addition to that. The third time, however, since we are using the result from the second countSort which we know two digits have already been sorted, we are sorting by two more digits! In summary, at iteration , we know is sorted by the first characters, so the next iteration doubles the amount of digits that are sorted. This is because we are sorting by -values, which are indices telling us the sorted order of partners with respect to their first characters. When , everything is sorted.
Analysis
Building
- Recall countSort uses time and where is the number of digits.
- Building suffix array takes iterations of countSort, so overall the process takes time.
Searching
- Binary search on suffix array takes comparisons as there are suffixes for a text of size .
- Each comparison is a
strcmpwhich takes . Thus overall searching takes .
Space
- Suffix array is slightly slower than suffix tree but it saves a lot of space compared to suffix tree.