Range Search
CS240E: Data Structures and Data Management (Enriched)
David Duan, 2019 Winter
Range SearchCS240E: Data Structures and Data Management (Enriched)David Duan, 2019 WinterPartition TreesQuadtreesExampleDictionary OperationsRange SearchHeight AnalysisRemarkskd-TreesExampleHeight AnalysisDictionary OperationsComplexityRange SearchRange Search AnalysisHigher DimensionsRange Trees(Balanced) BST Range SearchStrategyExamplePseudocodeAnalysis2D Range TreesSpaceDictionary OperationsNo Rotation in Primary TreeRange SearchHigher DimensionThree-Sided Range Query
Partition Trees
A tree with leaves where
- Each leaf node corresponds to an actual item, and
- Each internal node corresponds to a region.
Quadtrees
Given points in the place and assume all points are bounded by a box of the form 1, we construct a quadtree on as follows:
- Root node of the quadtree corresponds to the entire region .
- If contains or points only, then root is a leaf that stores the point.
- Otherwise, we partition into four quadrants: , , , and insert four subtrees , , , to the root of , where each is associated with .
- We recursively repeat this process at each subtree. Note that each recursive call ends when the regions has only one or zero point inside.
Example
Given the following points in the left, we recursively partition the square into smaller regions, until each region contains at most one point, i.e., the right picture.

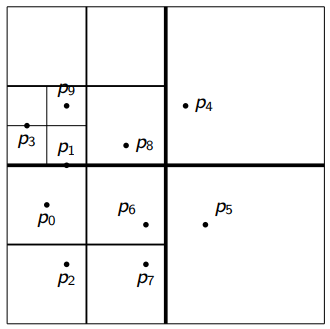
The computer stores the quadtree as shown in the left, but we could ignore the empty regions/nodes and instead label the edges.
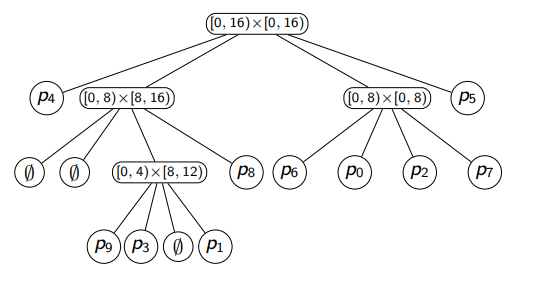
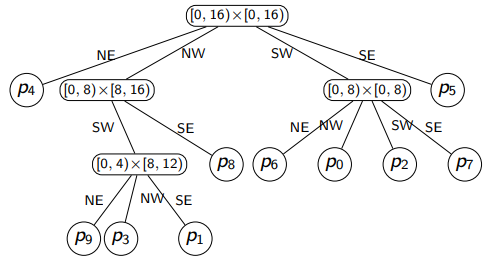
Dictionary Operations
Search: Analogous to BSTs and tries.
Insert: search for the new point (for where it should be), now split the region (repeatedly if necessary) until the new point is in a region of its own.
Range Search
Let be a quadtree, be the square corresponding to , and be our query rectangle. We can classify nodes in the quadtree as follows:
- Green: is green if potentially coincides with ; we need to further explore.
- Blue: is blue if is disjoint with ; we know it cannot contain any point we want.
- Pink: is pink if is a subset of ; every point in must also be in .
We have four cases to deal with:
- Base Case I: If , i.e., is a pink node, then every point in (i.e., every node in ) must be in . We report all points in and return.
- Base Case II: If , i.e., is a blue node, then every point in (i.e., every node in ) must not be in . We discard them (by doing nothing) and return.
- Base Case III: Now must be green. If , i.e., contains only one node (i.e., contains one point), then we explicitly check if . We report it if yes / discard it if no and return.
- Recursion: Now is green and contains multiple nodes (i.e., contains multiple points). We call on each child (i.e., search each region).
Height Analysis
Define to be the spread factor of points in :
Then the height of a quadtree is bounded by
Note that if the minimum distance between two points are small, the height could very large.
Remarks
In 3D, we have oct-trees; in 1D, we get a trie! 2
kd-Trees
Instead of blindly cutting regions into the same size (Trie), we now split the points so that the set of points is cut in roughly half (BST).
On the first cut, we use a vertical line to split the dataset according to the -coordinates; on the next cut, we use a horizontal line to split each subset based on the -coordinates. We repeat this procedure until every point is in its own region.
To construct a kd-Tree with initial split by on :
- If , create a leaf and return.
- Else, define .
- Partition by -coordinates into and .
- Create left subtree recursively (splitting by ) for points .
- Create the right subtree recursively (splitting by ) for points .
Just like quadtrees can be seen as 2D tries, kd-trees can be seen as 2D BST or decision trees.
Example

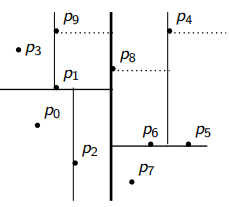
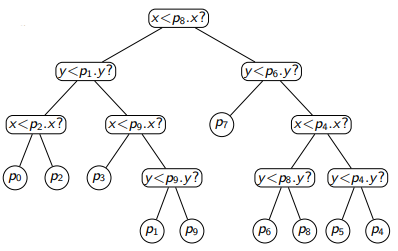
Height Analysis
Recall in construction procedure, we split along the line through the point that is -th in or direction. Thus, we have at most points in the bottom/left region, but we don't have a clear bound on the right/top side as we can't guarantee how many are sitting on the median line. For example, consider the following extreme case:
Our "decision tree" built here has an infinite height, because on each level, the left subtree is always empty and the right subtree contains the same elements; the problem size doesn't decrease as we go deeper into the tree. This shows us that kd-trees have even worse performance than quadtrees in theory.
However, given the input is nice (general position, i.e., no two or -coordinates are the same), if you split by the median, you are essentially creating a very balanced BST, where points on one side and the other side. Thus, the height is in .
Dictionary Operations
Search: Analogous to BSTs and tries.
Insert: To keep our height , we could track our height and rebuild a subtree after insertion if needed as in scapegoat trees.
Complexity
Build:
- Find the median (): expected.
- Split the points (one pass): .
- Recursion: expected.
Search: given the input is nice.
Insert: Amortized .
Range Search
The procedure for kd-trees are almost identical to quadtree's:
Range Search Analysis
Recall color coding from before:
- Green: is green if potentially coincides with ; we need to further explore.
- Blue: is blue if is disjoint with ; we know it cannot contain any point we want.
- Pink: is pink if is a subset of ; every point in must also be in .
We want to show that if the points are in general position (i.e., no coinciding coordinates), then there are green nodes. It is enough to show there are nodes for which the region intersects the left side of .
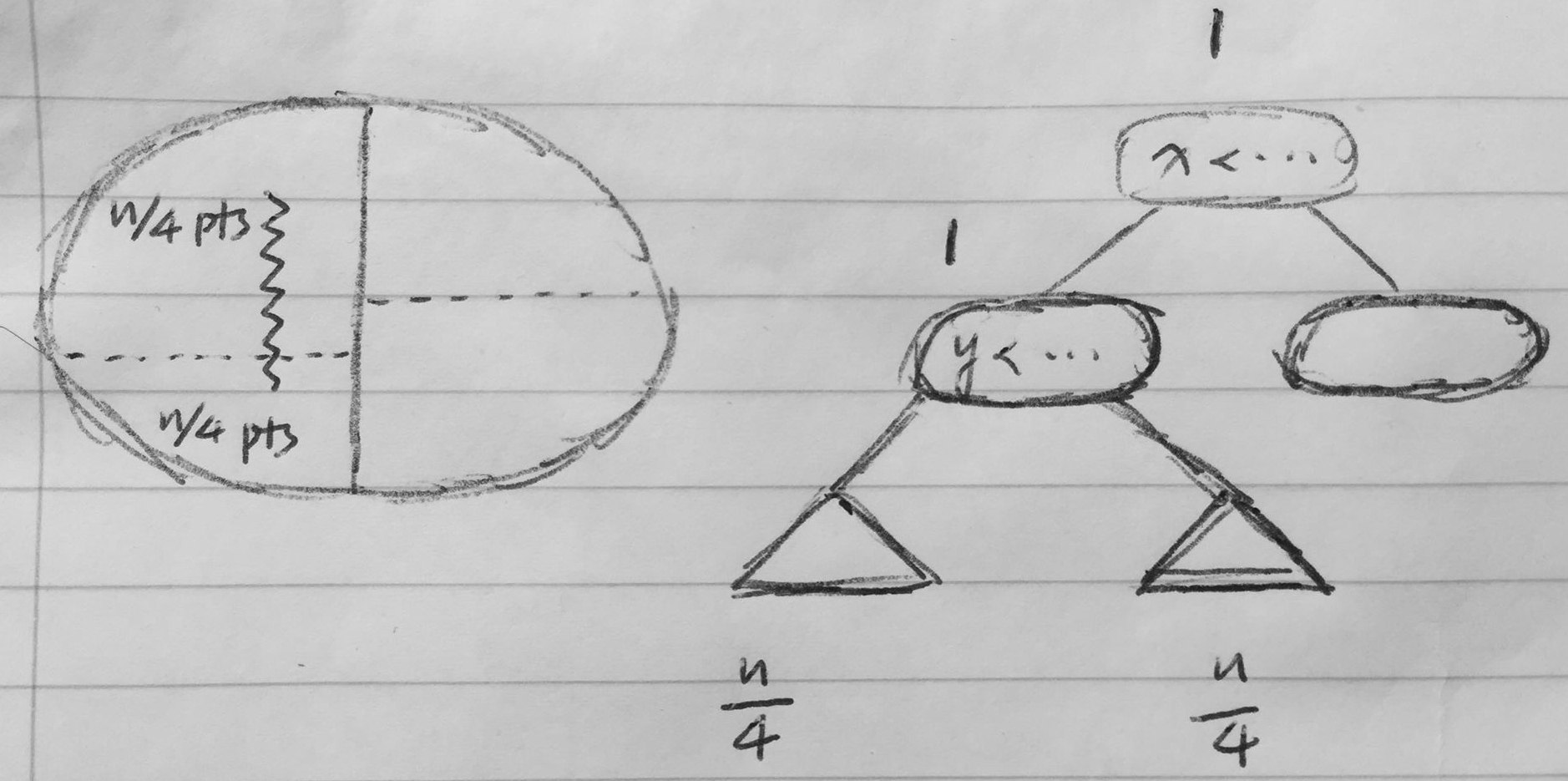
Let the squiggly line represent the left side of ; we want to count how many regions intersects it. During our first split, we can get rid of the right side as we know none of those nodes will intersect the line. During our second split, however, since we are cutting horizontally, we cannot guarantee one of the two sub-regions on the left side has no node intersecting the line. Thus, we must check both sub-regions next time. Therefore, we need to process nodes (both sub-regions on the left side) plus the green nodes we just processed (root node and second layer ).
More strictly speaking, let be the number of nodes in a kd-tree that stores points whose region intersects a vertical segment. We have the following recursion:
Therefore, given the tree is balanced (i.e., the input is nice), the comlplexity of a range search in kd-trees is where is the size of output.
Higher Dimensions
For a -dimensional space,
- At the root the point set is partitioned based on the first coordinate,
- At the second layer the partition is based on the second coordinate,
- ...
- At layer the partition is based on the last coordinate,
- At layer we start all over again, until each point has its own region.
Complexity (assume that points share coordinates and is a constant):
- Space: .
- Construction: .
- RangeSearch: .
Range Trees
We now present a new data structure which provides much faster range query operation but requires more than linear space.
(Balanced) BST Range Search
Strategy
Search for in : returns a path .
Search for in : returns a path .
Partition nodes of into three groups:
- Green/boundary node: on or ; check each green node to see if it is in the search range.
- Blue: definitely not in the range, so you are either a left child in where goes right, or right child in where goes left.
- Pink/allocation node: coordinates are definitely in the range; the "inside nodes".
Report all allocation nodes; test each boundary node and report it if in range.
Example
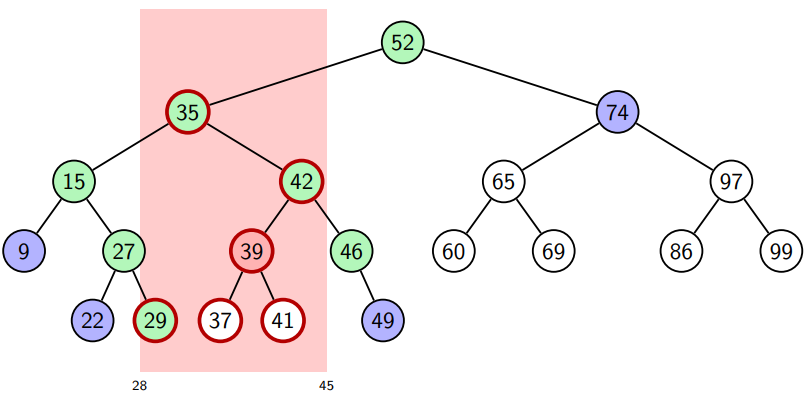
; .
Pseudocode
The following algorithm returns keys in that are in range in sorted order.
Analysis
Assume the BST is balanced. Then so we have boundary nodes; testing each of them requires time. Next, recall is an allocation node if it is not in or but its parent is (not both); if parent in , is a right child; if parent in , is a left child. Since query stops at the topmost level (of allocation nodes) and there are nodes on and , they take time. Finally, reporting all results takes , so overall time.
2D Range Trees
Given points , a range tree is a tree of trees (a multi-level data structure), where
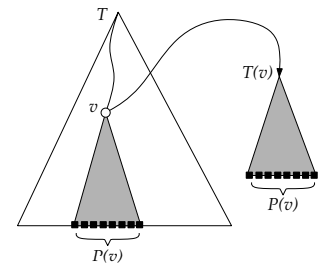
- Primary: Scapegoat Tree, called -tree, as it uses -coordinates as keys.
- Auxiliary: Balanced BST, called -tree, as it uses -coordinates as keys.
Every node in the primary data structure has an associated data structure, which contains the same set of descendents of this node, but potentially in a different order.
Space
Note that each point is in the associated data structure for all its ancestors. Since we are forcing a scapegoat tree as the primary data structure, each node has ancestors. Thus, each node is in associated trees. There are nodes in the primary tree, the overall auxiliary space needed is .
Dictionary Operations
: Search for in the primary tree , time. Note that could exists repeatedly as coordinates, so we need to solve the tie-breaking rule to find all of them. The safest choice is to compare coordinates. Then search for in the associated secondary tree, time.
: Insert into the primary tree , time. For each of the nodes on the path to the insertion point, insert to the associated -tree, so overall .
No Rotation in Primary Tree
We don't want to rotate the primary tree, because then the associated trees will be messed up. Because we use scapegoat trees,
- We don't need rotations to guarantee height,
- When we rebuild a subtree of the primary tree, we also rebuild all associated trees of that subtree,
- We can show the amortized time is still .
Range Search
- Do a range query by -coordinates in primary tree ; color code each node as pink/green/blue: .
- For each green node, explicitly test whether the point is in range: .
- For each pink node, do a range query by -coordinates; each takes and pinks, so overall nodes.
Thus, we can do a range query in a range tree in time where is the output size.
Higher Dimension
Range trees can be generalized to -dimensional space (time-space trade-off compared to kd-trees:)
| Range Trees | kD-Trees | |
|---|---|---|
| Space | ||
| Construction | ||
| RangeQuery |
Three-Sided Range Query
Assume we query .
Idea I Use associated data structures.
Primary: scapegoat tree
Associated: binary heap (recall from A1, we could find all elements larger than in time).
Query:
- Query in the primary tree by .
- For each green node, test.
- For each red node ( of them), find all elements larger than in the associated heap.
- Overall: , where is size of output.
Disadvantage: wasting space.
Idea II Use treaps: combining BST with heaps.
Only structure: treap.
Query:
- to get boundary and allocation ondes.
- Boundary nodes: explicitly test each.
- Allocation nodes: search in each heap.
Disadvantage: We cannot bound the height for treaps.
Idea III Separate where the point is stored from the -coordinate used for split.
- No detail for this one.